在別人的blog上看到的,轉自哈佛管理世界
留在這裡做個分享:
一:沉穩
(1)不要隨便顯露你的情緒。
(2)不要逢人就訴說你的困難和遭遇。
(3)在徵詢別人的意見之前,自己先思考,但不要先講。
(4)不要一有機會就嘮叨你的不滿。
(5)重要的決定儘量有別人商量,最好隔一天再發佈。
(6)講話不要有任何的慌張,走路也是。
二:細心
(1)對身邊發生的事情,常思考它們的因果關係。
(2)對做不到位的執行問題,要發掘它們的根本癥結。
(3)對習以為常的做事方法,要有改進或優化的建議。
(4)做什麼事情都要養成有條不紊和井然有序的習慣。
(5)經常去找幾個別人看不出來的毛病或弊端。
(6)自己要隨時隨地對有所不足的地方補位。
三:膽識
(1)不要常用缺乏自信的詞句
(2)不要常常反悔,輕易推翻已經決定的事。
(3)在眾人爭執不休時,不要沒有主見。
(4)整體氛圍低落時,你要樂觀、陽光!
(5)做任何事情都要用心,因為有人在看著你。
(6)事情不順的時候,歇口氣,重新尋找突破口,就結束也要乾淨俐落。
四:大度
(1)不要刻意把有可能是夥伴的人變成對手。
(2)對別人的小過失、小錯誤不要斤斤計較。
(3)在金錢上要大方,學習三施(財施、法施、無畏施)
(4)不要有權力的傲慢和知識的偏見。
(5)任何成果和成就都應和別人分享。
(6)必須有人犧牲或奉獻的時候,自己走在前面。
五:誠信
(1)做不到的事情不要說,說了就努力做到。
(2)虛的口號或標語不要常掛嘴上。
(3)針對客戶提出的"不誠信"問題,拿出改善的方法。
(4)停止一切"不道德"的手段。
(5)耍弄小聰明,要不得!
(6)計算一下產品或服務的誠信代價,那就是品牌成本。
六:擔當
(1)檢討任何過失的時候,先從自身或自己人開始反省。
(2)事項結束後,先審查過錯,再列述功勞。
(3)認錯從上級開始,表功從下級啟動。
(4)著手一個計畫,先將權責界定清楚,而且分配得當。
[Timeless way of Building] Pattern and Code Convention
Code Convention 是一連串Pattern的集合
Pattern是從許許多多解決問題的方法中,所找出來的,具有共通性的解法
Pattern是從context中誕生出來的,並由人命名而成為design pattern
Timeless way of building中,提到了好的建築中會有的Pattern
包括窗戶的大小,坐北朝南,房間的位址等等.
這些Pattern並沒有名稱,但是卻讓建築更為美好而偉大
我們稱為Quality Without A Name
而好的code也必須要有這些QWAN
1.一致性 : 大雜院 vs 社區
在code project中,我們時常會看到多種不同的寫法,
難以理解的命名與無法找到檔案的目錄架構
有統一的Convention可以讓檔案結構更容易理解
ex : 美國街道的street vs avenue,street為東西向,avenue為南北向,讓人一看就知道這條路往哪個方向
ex : 傳統的專案架構: doc,bin,obj,src...
ex : Pascal , _Camel等命名方式
2.更好的寫法Pattern與設計的指導原則
ex:使用多個if()來取代巢狀的if-else
ex:制定exception handle的規則
ex:遇到不知道的情況以簡單的方法優先
ex:使用String.isNullOrEmpty()來檢查空字串
3.讓犯錯變得困難
制定checkin policy : 於SourceControl設定code的檢查原則,要違反必須要設定attribute
使用using的關鍵字來管理連線,避免浪費連線資源
(Javascript)使用(function())()這種closure pattern來保持namespace的清潔
Pattern是從許許多多解決問題的方法中,所找出來的,具有共通性的解法
Pattern是從context中誕生出來的,並由人命名而成為design pattern
Timeless way of building中,提到了好的建築中會有的Pattern
包括窗戶的大小,坐北朝南,房間的位址等等.
這些Pattern並沒有名稱,但是卻讓建築更為美好而偉大
我們稱為Quality Without A Name
而好的code也必須要有這些QWAN
1.一致性 : 大雜院 vs 社區
在code project中,我們時常會看到多種不同的寫法,
難以理解的命名與無法找到檔案的目錄架構
有統一的Convention可以讓檔案結構更容易理解
ex : 美國街道的street vs avenue,street為東西向,avenue為南北向,讓人一看就知道這條路往哪個方向
ex : 傳統的專案架構: doc,bin,obj,src...
ex : Pascal , _Camel等命名方式
2.更好的寫法Pattern與設計的指導原則
ex:使用多個if()來取代巢狀的if-else
ex:制定exception handle的規則
ex:遇到不知道的情況以簡單的方法優先
ex:使用String.isNullOrEmpty()來檢查空字串
3.讓犯錯變得困難
制定checkin policy : 於SourceControl設定code的檢查原則,要違反必須要設定attribute
使用using的關鍵字來管理連線,避免浪費連線資源
(Javascript)使用(function())()這種closure pattern來保持namespace的清潔
[Translation]The SQL high performence series part II
偷懶了兩個月沒有寫文章,目前差不多也適應了新的環境
就以利用空閒時間翻譯的這篇文章作為blog復活的開始吧
原文:The SQL high performence series part II
這篇文章是三篇系列文的第二篇(不過作者於第三篇富監了),裡面對索引以及資料庫是如何決定搜尋計畫有不錯的說明
基本?我們可都是專家!
大部分於這篇文章中提到的內容對許多開發者都是老生常談, 但還是值得複習 – 即使在專家之間對於資料庫的基礎,以及影響系統表現的重大原因,都還是留有誤解以及矛盾的資訊. 我將這篇文章寫的比較像一篇演講,而不是一張」重要清單」,但如果你只想看結論可以直接按End
Data Size
這需要在這裡被強調是因為有越來越多的"data wasters" 錯誤的相信只要他們浪費越多,這個專案就會越像一個"企業解決方案",我跳入這個泥沼,知道有些賺飽口袋的反對者會有"你在說謊"之類的回應,不過如果這樣做能夠多省下一byte tree的資料,我願意付出這個代價.
最小化你的資料,當你不需要GUID的時候,不要用GUID(例如:你不需要做跨全域的複製以及不重複的ID時),不要用bigint當你只需要int或small int, 不要用small int 當一個 tiny int就可以滿足需求,用varchar當你不需要nvarchar.使用最小並適合的資料型態,不要到了要刪減過大的資料時,才使用不明確的packing技巧或是原生資料型別.
當然你應該計畫現實上有可能的成長, 而且我並不是在鼓吹你需要用一個tinyint來儲存你的CustomerID欄位,但是在設計你的應用程式時要有一個合理的標準 – 你真的會有超過兩億的使用者嗎?你的應用程式會有32767種語言嗎? 有可能我們會面對一個需有兩億個月份的日曆系統嗎?
去估計在資料庫中使用這些大類別儲存較小的資料是不是可接受的妥協,這會增加效能,並且允許你能簡單的升級你的資料型別,當那些不太可能發生的需求成真的時候。
很明顯的有需多案子確實需要大資料型別的保障,但太多DBA用GUID或BigInt儲存資料以防萬一,來逃避效率上的責任(建立GUID也要花費資源,並且會增加儲存以及I/O的花費,當GUID被用來記錄網路卡的MAC位置時,GUID是循序性的,但現在Windows上的GUID只是單純的亂數, 作為叢集主鍵將會導致無止境的資料重新排列)這有什麼重要的?在實際的企業應用程式中,有好幾百萬的資料列在資料庫中,而又需要從像冰河一樣緩慢的儲存系統中讀取與寫入資料 – 在這些有限的資源中, 使用1MB來傳輸20000筆記錄不是比5000筆記錄來的好嗎? 10%的資料庫可以儲存到快取記憶體是不是比5%好呢?當然.
不要被那些小規模,所有資料都在記憶體而Query中的計算大於I/O費用的Benchmark所騙. 認為使用大的DataType隻影響了10%左右的表現 – 當你的資料庫進入真正的企業層級時, 尺寸真的很重要(size really does matter). 使用GUID當叢集式索引的主鍵不僅讓你的資料列更大, 也讓非叢集索引更大(並更慢), 當你SAN中最弱的一環正以100%在跑,你會後悔你浪費的每一個byte
索引
許多SQL Server表現上的問題都是源自於沒有或不正確的索引, 或是沒有用到的後補索引. 這常發生在前端專家不情願的接下資料庫的工作時,甚至是發生在由資料庫專家精心打造的資料庫中。
瞭解索引, 並專注於使用它們 , 是高效能資料庫最重要的一點. 不只是建立正確的索引, 還有如何正確的調整現有的索引.
非叢集索引
在參考書中的索引和資料庫中的索引有同樣的意義(並有很多相同的特徵),參考索引你可以快速的找到你想要的資訊,與掃過書裡的每一頁來找尋內容不同,可以直接找到你想要的頁面。在SQL Server的世界中這種索引稱為非叢集索引(non-clustered indexes或是Secondary indexes) - 他們是一個依特定目的而排序資料的子集合,包含了一個指向實體資料列的指標。
在Northwind 資料庫中Order Table的ShipPostalCode是一個非叢集索引的範例。這個索引由ShipPostalCode排序,並可能在下列的Query中使用。
如果你看一下執行計畫(當你執行Query時按Ctrl + K 或點選"顯示執行計畫",執行計畫會出現在下方的結果分頁中),你可以看到索引查找(index seek)的發生,並執行一個Bookmark lookup來找到原始的資料列。如果我們在執行以上的Query前先執行SET STATISTICS IO ON,我們會得到此Query的IO使用量統計報告,會像以下這樣:
Table 'Orders'. Scan count 1, logical reads 4, physical reads 0, read-ahead reads 0.
比較不會使用到索引的以下Query:
SELECT * FROM Orders WITH(INDEX(0)) WHERE ShipPostalCode = '05022'
在這個案例中執行計畫顯示了完整的資料表搜尋(full table scan),IO統計報告如下:
Table 'Orders'. Scan count 1, logical reads 21, physical reads 0, read-ahead reads 0.
在沒有索引的情況下明顯的使用了更多I/O,如果資料量增加到企業級的數量的話,這情況會變得更糟.讓這個事情更糟的是,每一次的資料表搜尋(table scan)會產生Page/row lock, block掉整個資料表的讀取,讓接下來的交易必須等待資料被unlock之後才能確定需要的資料在不在那些被鎖定的資料之中.可是索引查找(index seek)能知道被鎖定的資料並不是他要搜尋的資料,所以不會被影響.試試看同時在兩個分開的查詢視窗中跑兩句query(如果你不能夠在30秒內很快的切換查詢視窗,可以增加WAITFOR的延遲)
BEGIN TRAN UPDATE Orders SET OrderDate = '1997-08-27' WHERE OrderID = 10647 WAITFOR DELAY '00:00:30' ROLLBACK TRAN
第一句使用索引的Query, 會忽略row lock資料列馬上回傳結果,因為被鎖定的資料列並不是這個query所要尋找的. 但第二句沒有使用索引query(可能因為沒有建立索引,或索引不是最佳搜尋選擇),會被block到另一個連線的鎖定解除. 不使用索引不只是非常的沒有效率,當資料庫增加規模時,也可能讓blocking問題顯著的惡化(或在嘗試增加規模時)
叢集式索引
回到我們的譬喻,許多書更進一步的將他們的內容排序,讓資料本身就是排序好的索引,一本料理書可能是按照料理名稱排序,或是一本電話簿是按照城市,姓,名來排列.所以如果你想在這些排好序的資料中搜尋,是非常的有效率的 - 在電話簿的例子中,你可以很快的找到你想找的城市以及姓名,然後在一小筆的資料中掃瞄你想找的人.在SQL server中這種排序叫做叢集式索引.(資料本身的排序),並且有很明顯的原因在一本書或一個資料表中只能有一個叢集式索引.它主要的優點就是所有符合索引的資料都可以迅速的提供,不用其他的參照.
在Northwind資料庫中使用下列的Query:
SELECT * FROM Orders JOIN [Order Details] ON Orders.OrderID = [Order Details].OrderID WHERE Orders.ShipPostalCode = '05022'
如果你檢視執行計畫,Order Details的資料會由一個有效率的索引查找(index seek)來取得.
不過叢集式索引並不是萬靈丹. 例如說,想像你是一個努力工作的打字員,正在維護一本電話簿的排版,然後你小心的將每一筆資料放在正確的頁面上.每次一筆新的資料進來,它並不會正好就符合排序資料的尾端,或是有時候改變已經存在的資訊會同時改變它的排序(例如說Smith先生改名成Jones),你需要重新排列一些頁面已取得空間.這些資料碎片的問題在非叢集與叢集索引都會發生, 但叢集式索引由於包含所有資料,所以這個問題特別嚴重.
當然你可以在每一頁預留一些空間放置這些資料來讓一些小的更動容易些,也就是在SQL Server中fillfactor(填滿因數)的目的(一個較低的fillfactor會在分頁留下更多的空間但會減低真正的資料密度 - 插入資料的速度增加,但讀取資料的表現則減少. 一個較高的fillfactor增加資料密度並提升讀取速度,但增加插入操作時會造成分頁的可能性.注意fillfactor只在索引建立時與重組/重建索引時有用),不規則的插入資料或經常改變叢集式索引欄位可能是會一個嚴重的效能問題.因為這個問題很多開發者使用單一的遞增ID 欄位來作為叢集式索引.歷史上來說有個原因是因為有複數且相同的欄位資料作為索引插入時,全部會被放到相同的索引底下,結果會在這個熱點導致資料的爭奪.SQL Server有邏輯可以解決這些ID欄位並有效的消除這些熱點的問題.
另一個叢集式索引的問題是他們的長度(他們包含了整個資料列的資料). 當你在找某一個特定的資料欄位時,其他資料有可能並不相關,或是你真的計畫在查找後使用所有的資料,但如果你查的是一個範圍內的資料(例如說在Oakville city姓Forbes的人的所有名子)資料庫引擎會使用範圍掃瞄(range scan)讀取整行的資料來找尋符合的資料,再抽出需要的資料. 在我們的電話簿例子中這小小的額外資料並不算什麼,但在真實世界的大型的資料表上可能會導致效能上的衝擊.
考慮如果我們有第二個用city,姓,名來排序的索引,資料庫引擎可以很有效的搜尋這些較小的索引內容.
覆蓋索引(Covering Indexes)
這個帶來一個重點 - 有些索引本身就包含足夠的資訊使你不需要去讀取內容,你的搜尋只要讀取索引就能滿足需求了.考慮一本旅遊書的索引,將有名的景點以國家,城市與名稱排序,然後將你導向更多資訊的頁面,如果你只是想知道義大利的Accademia dell' Arte del Disegno在什麼城市,快速的搜尋索引就可以知道他在Florence. 在這個例子中索引為"覆蓋索引(covering index)",包含了可以覆蓋需求的所有資訊,讓我們不需要去查找資料列來找尋需要的資訊,這常常是最有效的搜尋機制.
變化之前範例中的query:
SELECT OrderID FROM Orders WHERE ShipPostalCode = '05022'
這會很有效的使用ShipPostalCode索引來找尋特定的紀錄,並且這個索引完全可以滿足query本身,所以可以避免消耗資源的bookmark lookup,IO也可以被最小化.
Table 'Orders'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0.
有人應該已經觀察到OrderID實際上並不在索引ShipPostalCode裡,或至少不應該在.但有趣的是所有已排序的資料中的叢集式索引欄位,會自動被加到其他索引的欄位中. 當你需要一個叢集式索引欄位的資料時,有可能非叢集索引的資料會立即滿足你,但也必須衡量它會讓每個其他的索引更大,導致更低的資料密度.
小型的覆蓋式索引是取得資料最有效率的方法,也是一個讓你確認你只取出你實際需要資料的理由.範圍掃瞄(Range Scan)在很多情形下也是很有效率的,並且通常在需要的資料在索引中是連續的的時候,像是你用BETWEEN搜尋兩個日期之間的資料時.雖然因為之前提過的bookmark lookup的花費, 範圍掃瞄(Range Scan)只在索引能完全覆蓋或是使用叢集式索引來搜尋的時候才能看到.
即使在完整的搜尋為必要的時候,索引仍然可能完全覆蓋,考慮加下來加入Customer table的索引:
CREATE INDEX CountryCity ON Customers(Country,City,Address)
這個索引當然包括了Country,City,Address,但如之前提過的它也包含了CustomerID因為它是叢集式索引.單然如果我們搜尋Country,或是Country與City,或是Country,City和Address一個很有效的搜尋或是範圍掃瞄(Range Scan)可能會用來找出符合的資料.
SELECT CustomerID FROM Customers WHERE Country = 'Canada'
如果我們只搜尋address呢?在這個情況下索引不能被用到因為他是先以country再以city與address排序的,所以一個特定的地址有可能出現在索引的任何位址
SELECT CustomerID FROM Customers WHERE Address = '43 rue St. Laurent'
你可能會很驚訝看到它仍然使用了索引, 儘管這次用的是很沒效率的掃瞄(scan)而不是查找(seek).索引因為覆蓋了query所有的敘句和傳回欄位而被使用,且因為索引只是資料的子集合,和資料表掃瞄(scan data table)比起來它使用較少的I/O來掃瞄整個索引
統計資料與bookmark
在之前的例子上我們跑了一個需要bookmark lookup的query(因為他沒有覆蓋索引).query如下:
SELECT * FROM Orders WHERE ShipPostalCode = '05022'
如果你觀看這個query的執行計畫可以看到它在索引中找尋"lookups",並且在叢集式索引上進行bookmark lookup,找尋真正資料列的資料.在這個案例中只有單一的傳回資料列,但即使如此,bookmark lookup的費用還是佔了50%的query運算費用.
bookmark lookup 的花費,是當一個item在索引中被找到,但索引並沒有包含所有需要的資料時所產生的,這也是為什麼很多人驚訝的發現SQL Server忽略了他們認為是完美的索引而使用資料庫掃瞄 (為什麼他們不用我的索引啊啊啊啊!!!). 考慮以下的query
SELECT * FROM Orders WHERE ShipPostalCode = '24100'從執行計畫你可以看到實際上進行了一個叢集式索引掃瞄 (是用叢集式索引進行的一個資料表掃瞄)來取代使用我們的索引,而且subtree的花費是0.0530
這也許看起來有些複雜,因為我們應該已經有了一個完美的索引,但讓我們重新執行一次相同的query,這次使用一個query hint來強迫他使用我們的索引
SELECT * FROM Orders WITH(INDEX(ShipPostalCode)) WHERE ShipPostalCode = '24100'
你可以從執行計畫上看到它使用了我們的索引,但這次bookmark lookups佔了所有執行時間的80%.我們的subtree花費變成了0.0564 - 比使用資料庫掃瞄還多!
在這個案例中只使用了總共830筆中的10筆記錄(1.2%),而它仍然選擇執行資料庫掃瞄而不是我們的索引.很多開發者都被這個情況迷惑,不知道為什麼SQL Server不使用他們美麗的索引,但資料庫引擎是因為非常實際的理由這樣做的 - 因為這樣比進行非直接從bookmarks的找尋每一小塊資料來的有效率.
當然我們可以儘可能的讓覆蓋索引包含所有必要的資訊來避免bookmark lookups,假設它包含了我們需要從資料表中取得的所有資訊:
SELECT OrderID FROM Orders WHERE ShipPostalCode = '24100'
現在它會使用我們的索引,而且超級有效率. 它的subtree花費只有0.0064.在大型的資料庫這些迴避bookmark lookup與資料表掃瞄的差異可能會非常大.
所以資料庫引擎是如何猜到有多少資料列會符合標準,來決定使用哪個方法最有效率?(不論是索引,bookmark lookup或資料表掃瞄) 這就是分散式統計資料(distribution statistics)派上用場的時候了. 統計資料(Statistics)是一個資料集合,資料庫引擎用來推測哪個計畫在這個查詢上最有效率.你可以用DBCC SHOW_STATISTICS 的指令來看到某些索引的統計資料,在以下的例子中為ShipPostalCode:
DBCC SHOW_STATISTICS('Orders','ShipPostalCode')
因為資料表中的ShipPostalCode是有範圍並分散的號碼,所以在這個例子中統計資料是完全正確的,在一個更實際的資料庫中,有上百萬行的資料列, 統計資料開始更接近估計(錯誤邊際值會逐漸增加),這些資料庫引擎的估計在某些極端的情形下可能會導致完全錯誤的假設,像是預測會產生幾千行資料但實際只用了幾行.
統計資料也可能在複數索引時出錯.在這個案例中可選擇的第一個欄位被使用到,所以之前我們建立的索引(Country,City,Address)因為Country的低辨識性(有很多相同的Country欄位),這個索引經常會被忽略,即使City與Address的結合是非常unique的. 所以普遍來說都建議使用可辨識性最高的欄位作為索引的第一個欄位,在這個案例的索引來說是Address,City,Country. 這是可以討論的因為它讓索引更具有單一的用途-他不再具有增進效率的用途,提供給比較模糊的搜尋像只有Country,或是Country/City. 但這需要依照案例來判斷,而且在一個完整正規化的資料表中,這並不是個問題.
並且需要注意的是,你的統計資料儘可能的接近正確值是很重要的. SQL Server包含了自動更新統計資料,依照預設值,在覺得資料已經過期時會自動嘗試資料取樣與更新統計資料. 但儘管如此,最好的方法還是定期的安排完整的統計資料更新(最少每週),最好使用WITH FULLSCAN 的選項讓結果儘可能的正確. 標準的database維護計畫包含了更新統計資料的步驟,允許你選擇取樣的資料範圍.
但即使依照以上的步驟,你的統計資料仍然有過期的可能. 在這種情況下可能是索引提示需要被加入query,來要求query重新評量. 不過很明顯的這應該是最後才考慮的手段.
實際使用索引
所以你已經建立了美麗的索引,然後你已經確定了你的query只從每個資料表中提取了必需的資料,在可能的地方使用覆蓋索引來避免bookmark lookup的花費. 你使用執行計畫來評量效能,並發現......資料庫引擎完全忽略了你的索引. 以下幾點是可能的原因.
考慮以下的query
SELECT OrderID FROM Orders WHERE LEFT(ShipPostalCode,4) = '0502'
很簡單的query, 而且看起來這像是一個很有效率的覆蓋索引查找(covered index seek). 但執行後會發現這其實是一個沒有效率的掃瞄.考慮下列query:
SELECT OrderID FROM Orders WHERE ShipPostalCode LIKE '0502%'在這個案例中query以高效率的索引查找(index seek)執行. 我已經有過這種微小的差距讓企業報表產生的時間從幾小時降到幾秒鐘的案例.
原因是因為前一個敘句的索引欄位被隱藏在函式之中. 資料庫引擎不能夠預測函式的結果是什麼,所以他會強迫去計算每一列的來看產生的結果. LIKE是第一級的比較函式,資料庫知道他的行為,所以可以對他做最佳化. 有無數的案例是由於人們沒有必要的將索引欄位放到了函式中,造成了大量與無法預期的效率低落.
最常見的例子是使用DATAADD/DATEDIFF來取得一定時間內的資料列 - 而不用預先計算好的數值(例如: GateDate() - 3 years) 並與資料列進行直接的比對, 開發者強迫整個資料庫掃瞄在每一個資料列上進行無謂的資料比對. 考慮一個從新聞資料表報告12小時內所有新出現新聞的query.
DECLARE @CurrentTime SET @CurrentTime = GetDate() SELECT * FROM NewsStories WHERE DATEDIFF(hh,NewsDate,@CurrentTime)<12
我保證這會非常的沒有效率, 但這也是非常普遍的例子. 使用下列變數,資料庫引擎可以更有效的最佳化:
DECLARE @StartTime SET @StartTime = DATEADD(hh,-12,GetDate()) SELECT * FROM NewsStories WHERE NewsDate > @StartTime
資料庫速查表:
索引欄位
在文章開頭我建議你們最小化使用的資料空間(增加實際資料密度). 這個目標並不是要將資料庫移植到一張磁片上,而是最小化查詢計需的磁碟I/O,因為磁碟I/O是企業系統中最脆弱的一環. 當然增加而外的索引,是一個設計上的選擇.它雖然會增加資料庫的大小但卻能減低實際上需要存取的I/O,所以通常都是很值得的交換.
另一個有用的技巧是,你可以以磁碟空間交換資料庫的效能,有很多的變化,但我只提一個最常使用的情形 - 依照年份提供每個月份的報表. 在這個情形下Orders 資料表可能被壓縮成用以下的Query來查詢:
SELECT YEAR(OrderDate) AS [Year], MONTH(OrderDate) AS [Month], COUNT(*) AS [Monthly Orders] FROM Orders WHERE YEAR(OrderDate)=1997 GROUP BY YEAR(OrderDate), MONTH(OrderDate)
取代使用串接式的命令來取得年分與月份的資料,考慮把它們加為資料欄位:
ALTER TABLE dbo.Orders ADD OrderDateYear AS CONVERT(smallint,YEAR(OrderDate)), OrderDateMonth AS CONVERT(tinyint,MONTH(OrderDate))
現在我們可以把query改成
SELECT OrderDateYear AS [Year], OrderDateMonth AS [Month], COUNT(*) AS [Monthly Orders] FROM Orders WHERE OrderDateYear=1997 GROUP BY OrderDateYear, OrderDateMonth
本身我們並沒有用任何方法來增加查詢的效率(事實上查詢效率在變更之後還降低了),雖然我們讓資料庫更複雜化,但我們也建立了一些索引欄位作為建立索引的基礎.
CREATE NONCLUSTERED INDEX IX_OrderDateDecomposed ON dbo.Orders ( OrderDateYear, OrderDateMonth ) ON [PRIMARY] GO
現在參考這些索引欄位的查詢戲劇性的便的非常有效率,更好的是,這些增加的索引欄位並沒有減低實際的資料密度,因為他們只出現在索引中. 注意:確認不需要這些索引欄位的查詢不會外在的或隱含的使用浪費的* column selector, 因為它會不必要為每一個資料列評估這些欄位.
索引視圖
[這個功能只在Enterprise和Developer edition of SQL Server才有]
一個索引視圖,有時候代表了一個具體的視圖,是一個排列後的索引欄位,把儲存計算結果帶到了下一個階段.在一個之前的例子中我們將索引欄位組合在一起來增加資料組合的邏輯效能.我們可以把它做個改變來建立一個視圖(View)
CREATE VIEW dbo.OrdersByMonth WITH SCHEMABINDING AS SELECT OrderDateYear AS [Year], OrderDateMonth AS [Month], COUNT_BIG(*) AS [Monthly Orders] FROM dbo.Orders GROUP BY OrderDateYear, OrderDateMonth
這個視圖(View)只是一個查詢的範本,並且只對重用程式碼有用(雖然也是個很有價值的目標).我們可以更進一步的實體化這個視圖(View),儲存結果並更改它,使更改內容能反映到實際的資料.以下的指令可建立一個索引視圖:
CREATE UNIQUE CLUSTERED INDEX IX_OrdersByMonth ON OrdersByMonth(Year,Month)
現在以下的查詢可以滿足索引視圖了,使用預先計算的值來取代每次查詢的重新計算.
SELECT [Year],[Month],[Monthly Orders] FROM OrdersByMonth WHERE Year=1997
最後我們每個月的訂單查詢使用的資源比原本的下降了90%,這還只是在一個很小的sample資料庫的結果.在真實的資料庫中結果可能差距會非常大.
索引視圖的確有缺點,像是會在資料改變的時候執行自動維護,但這可以是一個非常有用的工具,當你的工具箱中有這項工具並且你使用的平台支援它的時候.
結論 :
- 儘可能保持資料列很小, 增加資料密度
- 所有的Table都需要叢集式索引,除了一些例外. 通常單一欄位的主鍵就是索引
- 小的叢集式索引讓非叢集式索引也很小,增加資料密度
- 叢集式索引可幫助建立其他覆蓋索引
- 使用覆蓋索引非常的有效率
- 避免把標準欄位隱藏在函式中 – 他們不能用到索引
- 當適合的時候使用有索引的欄位
- 如果你已經花錢買了企業板的資料庫,認真考慮使用索引視圖(indexed view)
- 索引索引索引!只有很有限的案例中,新增與插入時維持索引的費用會超過它的好處
- 瞭解執行計畫,定期的去評估它
[.Note]jquery動態調整欄寬&限制checkbox選取
幾個專案上遇到的小需求,
皆用JQuery來解決,在這裡記錄一下解法
有一個table,他的第一個欄位長度是固定的,後面的欄位要有相等的寬度,
但是後面的欄位數目是動態產生,欄位的名稱長度也不固定,如果欄位過長則必須要換行
一開始是用%數的方法來指定欄寬長度,但是這個方法並不能夠有效的在所有瀏覽器上運行
後來使用jquery來動態調整欄寬 : 先等table產生,再計算出後面欄位的平均寬度,並將儲存格寬度調整為平均寬度:
有一個多選的CheckboxList,需要限制最大的選取數量
如果超過則不能選擇:
有一個問卷題型叫排序題,結構上是由許多RadioButtonGroup所構成,
讓使用者能排列喜好選項的順序 : (ex, 有三個選項, 可以選擇 3,2,1 或 1,2,3的排序 )
但使用者希望能夠有防呆機制,讓已經於其他選項選過的排序不能再選第二次
(ex:三個選項的排序可為 1,2,3. 3,2,1 . 但不可為 2,2,1 )
後來選擇了一個比較簡單的作法:當排序被選取時,清空其他有同樣排序值的RadioButton
以上的需求如果使用Javascript不知道要做多久...
所以說JQuery真的是能夠有效增加前端生產力的一個好框架啊,
只要有用到Web的開發者真的都需要接觸一下
皆用JQuery來解決,在這裡記錄一下解法
1.動態調整欄寬 :
有一個table,他的第一個欄位長度是固定的,後面的欄位要有相等的寬度,
但是後面的欄位數目是動態產生,欄位的名稱長度也不固定,如果欄位過長則必須要換行
一開始是用%數的方法來指定欄寬長度,但是這個方法並不能夠有效的在所有瀏覽器上運行
後來使用jquery來動態調整欄寬 : 先等table產生,再計算出後面欄位的平均寬度,並將儲存格寬度調整為平均寬度:
$('.sort').each(function() {
var sum = 0;
//取得所有要調整的欄寬
var cells = $(this).find('.sort-item');
//統計總寬度
cells.each(function() {
sum += $(this).width();
});
//設定平均欄寬
var cellWidth = sum / cells.length;
cells.each(function() {
$(this).width(cellWidth);
});
});
2.限制checkbox選取
有一個多選的CheckboxList,需要限制最大的選取數量
如果超過則不能選擇:
//傳入CheckboxList Container的ID
bindMultiSelectLimit = function(id,limit) {
$('#' + id + ' input:checkbox').click(function() {
//使用Jquery selector直接找出所有已選之Checkbox
if ($('#' + id + ' input:checked').length > limit) {
return false;
}
});
};
3.限制排序問題重覆選取
有一個問卷題型叫排序題,結構上是由許多RadioButtonGroup所構成,
讓使用者能排列喜好選項的順序 : (ex, 有三個選項, 可以選擇 3,2,1 或 1,2,3的排序 )
但使用者希望能夠有防呆機制,讓已經於其他選項選過的排序不能再選第二次
(ex:三個選項的排序可為 1,2,3. 3,2,1 . 但不可為 2,2,1 )
後來選擇了一個比較簡單的作法:當排序被選取時,清空其他有同樣排序值的RadioButton
//傳入ContainerID
bindSortRules = function(id) {
$('#' + id + ' input').click(function() {
//設定每個排序RadioButton有同樣的value,將其他有相同value的值都設為false
$('#' + id + ' input[value=' + $(this).val() + ']').attr('checked', false);
//設定目前選擇的值
$(this).attr('checked', true);
});
}
以上的需求如果使用Javascript不知道要做多久...
所以說JQuery真的是能夠有效增加前端生產力的一個好框架啊,
只要有用到Web的開發者真的都需要接觸一下
[soapUI]如何測試你的WebService
當我們開發WebService時,有一個問題就是我們要如何去測試WebService是否能成功的被呼叫,並且如何去建立測試案例來確認讓服務可以工作。
soapUI提供了完整的WebService相關測試功能以及介面,讓開發與測試WebService變得更容易
包括了呼叫WebService,建立測試案例, LoadTest ,建立Mock Service讓程式呼叫等等
在使用SOAPUI之前,須先對WebService的一些基本架構有些了解 :
WebService透過了WSDL (Web Service Definition Language)定義服務提供的介面,並經由架構在Http上的SOAP(Simple Object Access Protocal),來傳輸資料,所以在使用WebService之前,須先從url獲得服務定義的wsdl檔,再以SOAP呼叫服務,獲得回傳結果。
下載安裝檔(這裡是使用 soapui-x32-3_5_1.exe , win32 installer)

選擇專案名稱以及WebService之wsdl定義檔,建立project。

開啟sample request或按右鍵新增Request,進入Request editor
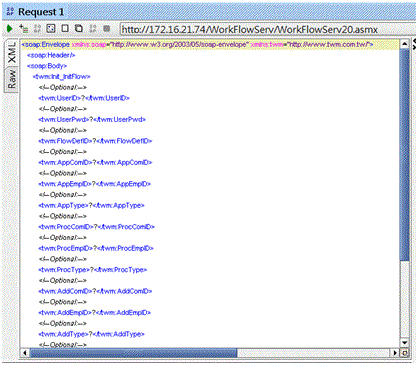
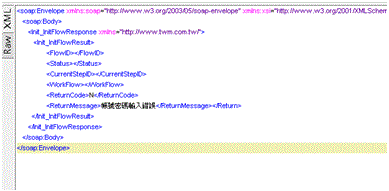
於問號處填入要傳入WebService的參數,並按左上角的箭頭執行呼叫,並取得回傳訊息,這樣就完成WebService的呼叫了。
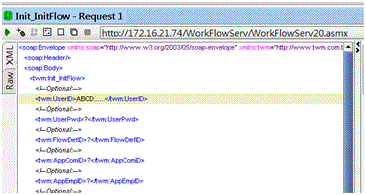
建立TestCase:
於Request處按右鍵,選擇Add to Testcase或於專案建立新的TestSuite

設定用來測試的參數
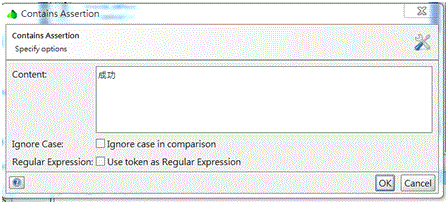
設定Assertion:
定義在什麼樣的情況下測試算是成功:
點選Request Editor的Assertion

選擇加入Assertion,設定Assertion的種類,這裡選擇Contains,會偵測回傳結果中是否包含指定的字串
測試:
按左上角執行測試,可以點選整個TestSuite,執行所有的TestCase並取得結果
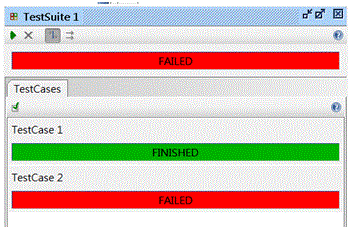
在有些情況下,會需要測試一連串的WebService步驟,並利用之前取得的結果作為下一個參數,在這裏我們可以利用TestCase的Property Transfer來移轉結果作為下一個Request的參數。

SOAPUI入門
soapUI提供了完整的WebService相關測試功能以及介面,讓開發與測試WebService變得更容易
包括了呼叫WebService,建立測試案例, LoadTest ,建立Mock Service讓程式呼叫等等
在使用SOAPUI之前,須先對WebService的一些基本架構有些了解 :
WebService透過了WSDL (Web Service Definition Language)定義服務提供的介面,並經由架構在Http上的SOAP(Simple Object Access Protocal),來傳輸資料,所以在使用WebService之前,須先從url獲得服務定義的wsdl檔,再以SOAP呼叫服務,獲得回傳結果。
0.安裝soapUI
從http://www.soapui.org/下載安裝檔(這裡是使用 soapui-x32-3_5_1.exe , win32 installer)
1.建立Web Service Project
File => New soapUI Project選擇專案名稱以及WebService之wsdl定義檔,建立project。
2.呼叫WebService
匯入wsdl後,專案底下會顯示所有可以呼叫的operation開啟sample request或按右鍵新增Request,進入Request editor
於問號處填入要傳入WebService的參數,並按左上角的箭頭執行呼叫,並取得回傳訊息,這樣就完成WebService的呼叫了。
3.建立測試
建立TestCase:
於Request處按右鍵,選擇Add to Testcase或於專案建立新的TestSuite
設定用來測試的參數
設定Assertion:
定義在什麼樣的情況下測試算是成功:
點選Request Editor的Assertion
選擇加入Assertion,設定Assertion的種類,這裡選擇Contains,會偵測回傳結果中是否包含指定的字串
測試:
按左上角執行測試,可以點選整個TestSuite,執行所有的TestCase並取得結果
建立連續的測試案例
在有些情況下,會需要測試一連串的WebService步驟,並利用之前取得的結果作為下一個參數,在這裏我們可以利用TestCase的Property Transfer來移轉結果作為下一個Request的參數。
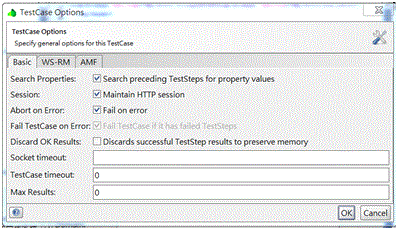
1.於TestCase Options勾選Maintain HTTP session
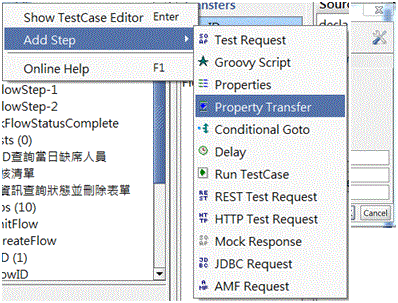
2.於TestCase加入Property Transfer步驟
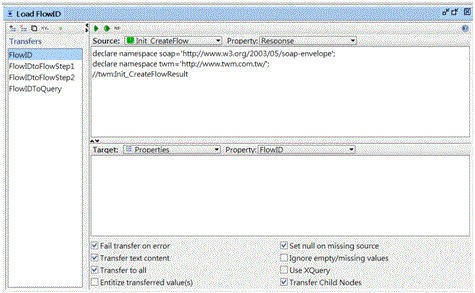
3.可以用Xpath的方式取得結果內的參數,將其移轉到下一個Request
(如果回傳值為xml字串的話,可以先將結果設為property,再用Xpath把需要的參數轉移到其他Request)4.Run Testcase
參考資料:
如何建立一個Test Project以及測試SOAPUI入門
[Continuous Integration]使用CruiseControl.NET實現持續整合
Continuous Integration,CI,中文稱為持續整合
在Martin Flower的網站有著定義如下:
http://martinfowler.com/articles/continuousIntegration.html
JosephJ也有一篇很好的介紹文章:
http://www.josephj.com/entry.php?id=251
每次有人commit code,功能作好了要佈署給使用者或Tester測試,
程式碼要執行測試與分析
要產生程式碼文件等等的時候
我們都是靠人工來執行整合的
每次都要把code checkout下來整合,執行一堆事情
更慘的是往往有人commit上了錯誤的程式碼,或漏掉一些元件
讓其他人update之後程式就不能跑了...然後花上時間去解決這些build problem
然後生命就浪費在這些無意義的事情上面
CI的意義就是利用srcipt的方式把這些工作整合起來
然後放在一個server上執行
只要有固定的script,這個整合步驟的執行頻率就可以提升到最多
可以每次有人commit就執行一次script,然後透過server,將產生的報告顯示在網頁上,或是以email的方式寄給大家,
最後自動將東西佈署到測試伺服器上
或是打包好可以使用,安裝
持續整合的例子 : Google Chrome 的Chromium BuildBot WaterFall
透過buildbot 執行多伺服器的Master-slave的持續整合架構
http://sites.google.com/a/chromium.org/dev/developers/testing/chromium-build-infrastructure/tour-of-the-chromium-buildbot
CruiseControl.NET是.NET平台一個open source的CI Server,
雖然在設定檔方面比較難以上手,需要用xml調整,
但是卻是適合沒錢和觀望的人嘗試CI的輕量級解決方案
Team City應該是比較好的選擇,只是要花錢
TFS則是很強大,和專案管理完全整合的重量級解決方案,不過要花錢
而且會與source control和其他MS的東西綁死
接下來會說明如何使用CCNET來持續整合一個簡單的專案 :
網路上也有很多說明文章:
http://omaralzabir.com/asp_net_website_continuous_integration_deployment_using_cruisecontrol_net__subversion__msbuild_and_robocopy/
這裡將會使用SVN,msbuild,mstest,msdeploy來作為持續建置的工具
從SourceForge下載CCNET:http://sourceforge.net/projects/ccnet/ 並安裝
安裝好了之後在安裝目錄下(C:\Program Files\CruiseControl.NET\server)
會有ccnet.config檔案
這是設定所有持續整合工作的主要設定檔
於ccnet.config加入一個專案與工作:
echo 'Hello CCNet!!'
然後執行CCNet.exe開始整合
連到http://localhost/ccnet, 可以從DashBoard看到專案建置的狀況,
並可以點選forcebuild來執行工作,從buildlog看到執行訊息
artifactDirectory:儲存專案建置的Log目錄
之後所有的tag都是放在區塊內
這裡使用的是SVN,現在也有對應git:
tips : 如果有裝Cygwin, commend line的svn 版本可能會是舊版,要先確認版本: svn --version
如果有憑證的話也要先手動接收一次,紀錄憑證訊息
這裡設定了檢查頻率為60秒,如果發現SVN上有變更就會update並執行整合
msbuild:
這裡使用visual studio的msbuild建置專案,msbuild的位置為
C:\Windows\Microsoft.NET\Framework\v3.5\MSBuild.exe
如使用.Net 4.0則要使用
C:\Windows\Microsoft.NET\Framework\v4.0\MSBuild.exe
並指定專案的.sln定義檔以執行建置
users:設定接收email的使用者
groups:設定接受通知的群組與原則:這裡設定只有在build failed與fixed才會收到通知
modifierNotificationTypes: commit的人在什麼狀況下會收到的email訊息:設定為failed與fixed
xslFiles:email中的訊息會由buildlog + .xsl轉換而來,這裡設定email buildreport要包含的訊息
設定Test會讓每次的Build收到測試案例的檢核,如果有TestCase失敗,build也會定義為失敗
deploy則是放在最後一個task,讓每個通過testcase檢核的commit會即時deploy到伺服器上
Mstest:
deleteTestResult.bat:
del testResults.trx
mstest必須要在build server安裝Visual Studio才會有
要指定測試專案中的\bin\debug\@TestProjectName.dll 執行
第一個task是為了刪除mstest的記錄檔testResults.trx而執行的script,不然mstest會告訴你因為已經有了log檔而無法測試
一般mstest的記錄檔名稱是自動產生,但這裡因為要將檔案merge到buildReport所以要指定檔名
詳細說明 : http://blogs.blackmarble.co.uk/blogs/bm-bloggers/archive/2006/06/14/5255.aspx
RoboCopy & msdeploy:
在區域網路的其他機器進行WebApp的deploy時,可以使用robocopy與檔案分享來deploy:
在確定整合工作沒有問題後,可以進入控制台=>服務 ,設定ccnet成為自動開啟的系統服務
於client端可以安裝CCTray,會於工作列新增一個小圖示,並隨時監控CI Server上的狀況
在Martin Flower的網站有著定義如下:
http://martinfowler.com/articles/continuousIntegration.html
Continuous Integration is a software development practice where members of a team integrate their work frequently,usually each person integrates at least daily - leading to multiple integrations per day. Each integration is verified by an automated build (including test) to detect integration errors as quickly as possible.Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive
software more rapidly.
持續整合是一個軟體開發的實踐,讓開發團隊裡的每個成員頻繁的整合他們的工作,使每天都會有許多次的整合.
每次的整合都都由一台自動建置伺服器來驗證以及執行測試,來盡快的偵測到每次的整合錯誤.
許多團隊發現到這個方法能夠有效的減少整合的問題,並且讓團隊能夠更密切的合作並快速開發軟體.
JosephJ也有一篇很好的介紹文章:
http://www.josephj.com/entry.php?id=251
為什麼要持續整合呢?
每次有人commit code,功能作好了要佈署給使用者或Tester測試,
程式碼要執行測試與分析
要產生程式碼文件等等的時候
我們都是靠人工來執行整合的
每次都要把code checkout下來整合,執行一堆事情
更慘的是往往有人commit上了錯誤的程式碼,或漏掉一些元件
讓其他人update之後程式就不能跑了...然後花上時間去解決這些build problem
然後生命就浪費在這些無意義的事情上面
CI的意義就是利用srcipt的方式把這些工作整合起來
然後放在一個server上執行
只要有固定的script,這個整合步驟的執行頻率就可以提升到最多
可以每次有人commit就執行一次script,然後透過server,將產生的報告顯示在網頁上,或是以email的方式寄給大家,
最後自動將東西佈署到測試伺服器上
或是打包好可以使用,安裝
持續整合的例子 : Google Chrome 的Chromium BuildBot WaterFall
透過buildbot 執行多伺服器的Master-slave的持續整合架構
http://sites.google.com/a/chromium.org/dev/developers/testing/chromium-build-infrastructure/tour-of-the-chromium-buildbot
CruiseControl.NET
CruiseControl.NET是.NET平台一個open source的CI Server,
雖然在設定檔方面比較難以上手,需要用xml調整,
但是卻是適合沒錢和觀望的人嘗試CI的輕量級解決方案
Team City應該是比較好的選擇,只是要花錢
TFS則是很強大,和專案管理完全整合的重量級解決方案,不過要花錢
而且會與source control和其他MS的東西綁死
接下來會說明如何使用CCNET來持續整合一個簡單的專案 :
網路上也有很多說明文章:
http://omaralzabir.com/asp_net_website_continuous_integration_deployment_using_cruisecontrol_net__subversion__msbuild_and_robocopy/
這裡將會使用SVN,msbuild,mstest,msdeploy來作為持續建置的工具
1.安裝CCNet:
從SourceForge下載CCNET:http://sourceforge.net/projects/ccnet/ 並安裝
安裝好了之後在安裝目錄下(C:\Program Files\CruiseControl.NET\server)
會有ccnet.config檔案
這是設定所有持續整合工作的主要設定檔
於ccnet.config加入一個專案與工作:
建立c:\projects\Hello.cmdHello CCNet c:\projects\Hello.cmd
echo 'Hello CCNet!!'
然後執行CCNet.exe開始整合
連到http://localhost/ccnet, 可以從DashBoard看到專案建置的狀況,
並可以點選forcebuild來執行工作,從buildlog看到執行訊息
2.設定ccnet.config
config檔的格式說明:http://confluence.public.thoughtworks.org/display/CCNET/Configuring+the+Server設定專案:
workingDirectory:專案的所在目錄CITestProject c:\projects\CITestProject c:\projects\CITestProject\Log
artifactDirectory:儲存專案建置的Log目錄
之後所有的tag都是放在
設定Repository:
這裡使用的是SVN,現在也有對應git:
設定url,使用者名稱與密碼,要checkout的目錄等等,建置伺服器上要安裝svnhttps://@SVNHost/CITestProject/trunk/ c:\projects\CITestProject BuildMaster ******** 36000000 false Always
tips : 如果有裝Cygwin, commend line的svn 版本可能會是舊版,要先確認版本: svn --version
如果有憑證的話也要先手動接收一次,紀錄憑證訊息
設定trigger:
trigger是指在什麼時候執行整合,有分固定時間執行或定期檢查Source有沒有更改兩種Trigger
這裡設定了檢查頻率為60秒,如果發現SVN上有變更就會update並執行整合
設定build task:
artifactcleanup:清除專案建置的logC:\Windows\Microsoft.NET\Framework\v3.5\MSBuild.exe C:\projects\CITestProject CITestProject.sln Clean;Build 300 C:\Program Files\CruiseControl.NET\server\ThoughtWorks.CruiseControl.MsBuild.dll
msbuild:
這裡使用visual studio的msbuild建置專案,msbuild的位置為
C:\Windows\Microsoft.NET\Framework\v3.5\MSBuild.exe
如使用.Net 4.0則要使用
C:\Windows\Microsoft.NET\Framework\v4.0\MSBuild.exe
並指定專案的.sln定義檔以執行建置
設定publishers: 如何以email或dashboard發佈專案結果
email:設定寄信的hostFailed Fixed Failed Fixed xsl\header.xsl xsl\compile.xsl xsl\unittests.xsl xsl\modifications.xsl
users:設定接收email的使用者
groups:設定接受通知的群組與原則:這裡設定只有在build failed與fixed才會收到通知
modifierNotificationTypes: commit的人在什麼狀況下會收到的email訊息:設定為failed與fixed
xslFiles:email中的訊息會由buildlog + .xsl轉換而來,這裡設定email buildreport要包含的訊息
3.Test and Deploy
以下為我用到的其他整合tasks,放在設定Test會讓每次的Build收到測試案例的檢核,如果有TestCase失敗,build也會定義為失敗
deploy則是放在最後一個task,讓每個通過testcase檢核的commit會即時deploy到伺服器上
Mstest:
deleteTestResult.bat C:\projects\ESurvey 300 C:\Program Files\Microsoft Visual Studio 9.0\Common7\IDE\mstest.exe C:\projects\ESurvey /testcontainer:CITestProject.Test\bin\Debug\CITestProject.Test.dll /runconfig:LocalTestRun.testrunconfig /resultsfile:testResults.trx 300 testResults.trx
deleteTestResult.bat:
del testResults.trx
mstest必須要在build server安裝Visual Studio才會有
要指定測試專案中的\bin\debug\@TestProjectName.dll 執行
第一個task是為了刪除mstest的記錄檔testResults.trx而執行的script,不然mstest會告訴你因為已經有了log檔而無法測試
一般mstest的記錄檔名稱是自動產生,但這裡因為要將檔案merge到buildReport所以要指定檔名
詳細說明 : http://blogs.blackmarble.co.uk/blogs/bm-bloggers/archive/2006/06/14/5255.aspx
RoboCopy & msdeploy:
在區域網路的其他機器進行WebApp的deploy時,可以使用robocopy與檔案分享來deploy:
或是使用msdeploy來佈署: http://www.iis.net/download/webdeployrobocopy.exe C:\Windows\System32 c:\projects\CITestProject\Web \\@DeployServerName\CITestProject /XD .svn /E /NDL /NC /NP /XO
msdeploy.exe C:\Program Files\IIS\Microsoft Web Deploy -verb:sync -source:contentPath="c:\projects\CITestProject\Web" -dest:contentPath="C:\project\CITestProject\Web",computername=@DeployServerName,username=administrator,password=******* -skip:objectName=dirPath,absolutePath=.*\.svn -skip:objectName=FilePath,absolutePath=.*\web.config
在確定整合工作沒有問題後,可以進入控制台=>服務 ,設定ccnet成為自動開啟的系統服務
於client端可以安裝CCTray,會於工作列新增一個小圖示,並隨時監控CI Server上的狀況
[.Note] 10 Things I Learned from JQuery Source (or more then 10?)
10 Things I Learned From The JQuery Source
From Paul Irish
一篇很棒的演講,由專家帶領我們從JQuery的原始碼中學習一些JQuery所用的JavaScript Pattern以及設計方式.
自從在OSDC2010上聽了Gugod的Less is More,JQuery這個框架的簡潔性以及設計的原則就一直吸引著我.
這個演講剛好讓我以後在用JQuery的時候能更輕易的去看source.
以下是筆記:
1.JQuery的Convention之一: Closure Pattern:
(function(){ ... })();
!function(){ ... }()
後面的括號代表這是self executing function: run itself immediately
favorite pattern:
(function(window,document,undefined){
....
})(this,document)
把window,document當成變數傳入closure,這樣的好處是:
1.如果有其他全域變數例如 undefined = true; // break all undifined comparison
而closure避免了這些干擾
2.minification:
最佳化後會變成: function(A,B,C){}(this,document), 可以省下一些字元
2. async recursion
Self repeating: 會不斷的執行,不論前一項有沒有執行完,
例如
setInterval(function(){
doStuff();
},100) // is very evil
而self executing function能確保執行到尾巴之後才會執行第二遍
(function loops(){
doStuff();
$('#update').load('awesomething.php',function(){
loops();
})
setTimeout(loops,100);
})()
3.如何找到函式: 找 function name + : , ex: "noConflict:"
4.Jquery.noConflict:
在開始時將 原本的 $ 儲存為 _$, 並在呼叫noConflict時復原.
5.jQuery.props
小型的參數字典,自動將Html與Dom Api上一些相同意思但名稱不同的參數作對應
讓開發者不需要記得所有的東西.
也可以用在.attr:
ex: WAI ARIA
$(elem).attr('aria-disabledby','asdasdasd');
$.props['adb'] = 'aria-disabledby';
=>
$(elem).attr('adb') = 'asdasdasd';
6. fadeIn() : defined your own speeds:
JQuery內部的 speed 定義了各種速度:
speeds: {slow:800 ,fast:200 ,_default:800}
可以由外部加入自訂的速度
jQuery.fx.speeds.fastopen= ($.browser.msie && $.browser.version < 8 ) ? 800 : 400;
//在IE7以下速度為800,其他瀏覽器為400
$('#stuff').fadeIn('fastopen');
7.JQuery.ready(...) 會檢查DOM準備好沒,在準備完畢時執行function,bindReady(); // IEContentLoad: solve by great Italian hacker,
using doScroll check to check if DOM ready in IE :
doScroll(left); //will raise exception if DOM not ready.
8.getJSON : shorthand methods:
jQuery ajax() holds anything, but get,post,getJSON,getScript shorten the varible.
9.selector performence.
$('#id') vs $('#id tag.thing')
$('#id tag.thing') will self parse to => $('#id').find('tag.thing');
$('#id').find('tag.thing')
$(':password') === $('*:password')
so better provide tagname ex: $('input:password');
10.getJSON: function protect 會用regex檢查資料是否為JSON,如果是的話就pass,
不是的話會呼叫 (new Function("return" + data))();
這叫Function constructor: 回傳
function(){return data;}
=== eval('('+data')');
但是避開使用邪惡的eval
11 $.unique(err) : duck punch
$.unique能夠過濾相同的DOM元素,讓陣列只有unique的元素
但不對應基本物件 使用duck punch來擴充unique方法:
(function($){
_old = $.unique()
if(!!arr[0].nodeType){
return _old.apply(this,arguments);
} else {
return $.grep(arr,function(v,k){
return $.inArray(v,arr) === k
});
}
})(jQuery);
12.quene: $(elem).fadeIn().delay(1000).fadeOut(); 可以使用quene方法改寫成
$(elem).quene(function(){
$(elem).delay(1000).fadeOut();
});
13.$.support
support使用一個HTML div,內部包含table,/a等等各項元素,
support會檢查瀏覽器能不能辨識其中的元素,來做瀏覽器的相容性檢查
14.bit.ly/jqsource : 一起來看JQuery Source
[Extension Method] 什麼是擴張方法??

什麼是Extension Method?
Extension Method可以將方法給"加"在現有的Class上:
舉例來說:
String.IsNullOrEmpty("Hello Ext");
有時候我會覺得這樣看起來有點不直覺...這時候就可以使用Extension Method來改寫,將IsNullOrEmpty給"加"在string物件之上:
public static class StringExtensions{
public static bool IsNullOrEmpty(this string content){
return String.IsNullOrEmpty(content);
}
}
string hello = "Hello Ext"
hello.IsNullOrEmpty();
...好吧,我承認這個例子有點無聊
不過Extension Method就像這樣,可以宣告靜態方法,並於compile時將這些方法附加於物件
而不需要修改物件的原始碼或是使用繼承關係
就像是動態語言的"Duck Typing",可以將行為附加在已經有的class上面.
How to use?
C#:1.將Extension Method宣告為靜態class以及靜態方法
2.第一個參數為this + 要附加的物件: IsNullOrEmpty(this string content)
VB
1.import System.Runtime.CompilerService
2.宣告Module,宣告靜態方法(shared),第一個參數為要附加的物件:
3.於方法前加入extension標籤: <Extension()>
Notice:
1.當extension Method與物件本身的方法衝突時,永遠是本體優先2.可繼承,影響到所有繼承的物件
那麼...為什麼要用Extension呢?
我的看法是,它可以很直覺化的將行為給附加在沒有原始碼,或是系統提供的物件上舉一個專案上碰到的例子來說:
Response.setHeader( "Pragma", "no-cache" );
Response.addHeader( "Cache-Control", "no-cache" );
Response.setDateHeader("Expires", 0);
是一段寫入取消快取的code,用extract function可以變成:NoCache(Response);但如果還有別的頁面要使用NoCache這個方法,NoCache要移到哪裡呢?
要獨立為靜態方法,還是抽出到base class呢?
Extension Method提供了一個最直覺的寫法:
Response.NoCache();
物件的操作與物件本身合為一體,只有Beautiful這個字可以形容了.
when not to?
在extension之外可以直接修改程式時,應該refactor away from extension method
在時常變更,或有繼承,多型關係的class最好不要使用,也無法附加到Static Class上
另外,如果實作於介面上:
1.會影響到每個實作介面的class
2.如果實作複數介面有可能會衝突
Extention Method Library
.NET本身就有一些物件是以Extension Method來提供擴充功能的,例如說一些LINQ方法,datatable的LINQ對應等等
Extention Method Library提供更多物件的擴充功能
像是int可以使用ruby like的 .times語法
4.times( (n) => Console.Writeln(n +" Times"); );
還有Session可以使用.Get<T>來指定型別
.Ensure<T>來確保不會拿到null值等等方便的擴張功能.
[3 way to estimate]估算專案時間的三種方法

為什麼軟體開發的時間難以估計?為什麼專案往往無法在預定時間內完成?
1.軟體開發的時間本來就難以估計
軟體開發本來就是個複雜的流程,除了許多複雜的邏輯與問題處理以外,
這個產業發展的速度太快,新的技術不斷的推出
使得每個專案都會遇到沒使用過的技術,沒有解決過的問題,即使是經驗豐富的開發者,
也不一定能準確的估算解決一個新的問題或技術要花多少時間.
2.軟體開發的需求,以及範圍經常變更
有許多的需求是隨著系統開發,使用者對於系統有更明確想法而產生的.
而在需求修改後,新的完成時間往往難以估算.
另外,專案開發一定必須debug,而debug的時間幾乎是完全無法預估,
許多的專案估算時間時沒有把debug與整合的時間算到專案開發時間內,
造成debug吃掉了本來應該用來開發的時間.
3.軟體開發有"技術債務",如果不維持品質,為了滿足短期交付而交出缺乏品質的程式碼,會導致後面的開發困難.
缺乏品質的程式碼的例子有:充滿大量剪貼的程式碼,許多用不到或浮誇的邏輯,
程式碼風格缺乏一致性,程式架構緊密偶合,肥大的class或頁面,沒有測試等等.
短期內這些問題並不會造成什麼嚴重的後果,但是就如"技術債務"這個詞所說的,
當這些問題沒有在發生的時候馬上處理,之後就要花上好幾倍的時間去處理這些債務.
估算專案時間的三種方法:
1:Time Base:
或稱為"Deadline Base",以專案的交付時間往回倒推.
例如說有三個月的開發時間,那麼就有2個禮拜作需求分析,2個禮拜做系統設計,5個禮拜開發,3個禮拜測試.
仔細一想就能明白,這個估算與實際上的開發內容完全無關,只是大致上的估算而已.
這種方式由來已久,並廣泛的用在各種行業與我們的生活,例如說考試前兩個禮拜要開始唸書
出國前3天要準備好護照與機票等等.
不過由於軟體開發的複雜性,這種方式並不能夠準確的估計專案的完成時間
2.Experience Base:
"經驗導向"為Time Base的延伸,基本上是去詢問工程師這個功能要做多久,
加上自己的經驗而判斷出來大概的時間,這種方式的準確度比較高,但是;
由於軟體開發的多變性與需求的變化,這並不一定能準確的估算,
而且人都有過短估計的傾向,與之相反的,
有時候這會變成"Promise Base",意思是要工程師在自己估算的時間準時交貨
但第一,估算一定與實際上要完成的時間與工作量有差距,這種估算方式就會導致
1.工程師儘量延長估算時間,避免無法完成
2.加班來達成自己的預估
3.延長完成時間以達成預估
比較好的作法是提供有彈性的預估範圍 -- 一個樂觀預估,一個一般預估.
3.Fact Base:
就是Agile裡的Burndown Chart,將系統切分為可重覆,類似的流程,
然後以過去開發的平均時間,來估算未來的完成時間,這種方法比較接近統計學
而且:
1.可以反映出開發者的速率,經驗較淺的人會花比較多時間完成同樣的項目,而這會反映在對整個專案速率的推估上
2.可以限制專案開發的範圍,因為完成時間是以功能/功能完成時間而推估,所以減少功能=提早完成時間,這個等式變得很明顯,也可以強迫負責人找出真正重要的功能去完成.
[Syntax highlighter & Prettify] 如何在網誌中加入語法高亮效果?
最近想要給之前貼的code加入一些語法高亮效果,讓code看起來比較清楚,
就survey了兩套javascript library,心得與安裝方法如下:
1.加入javascript與css到網頁上:
*http://jsgears.googlecode.com/svn/trunk/prettify.min/ 這裡有壓縮版(16KB)的檔案可以引用
2.於讀取網頁時執行語法高亮函式:
如果與其他設定重複了可加入Event Handler:
3.於想要加強語法效果處加入class="prettyprint":
1.加入基本的javascript與css設定:
2.加入要使用的語法以及css主題:
3.執行Syntax Highlighter:
在blogger要多設定bloggerMode= true;
還有為了執行剪貼簿功能要多load一個clipboard.swf,因為javascript不能存取剪貼簿
updated:最新的版本取消了這個功能,現在只要double click就可以選取全文
4.於想要加強語法效果處加入class="brush: [語法]":
可設定無行號的light模式:
可指定行號加入強調效果:
大小:兩者差不多,syntax highlighter要讀取比較多的語法檔與css主題,而prettify比較簡單
但syntax highlighter有官方的壓縮檔host
效果:syntax highlighter效果比較好,有行號,高亮,還有各種不同主題與剪貼簿功能
對應語言:各有長處,但syntax highlighter的語法檔比較好懂
不過最後我發現prettify在ie7會有把多行擠成一行的bug,
所以決定用Syntax Highlighter了 :)
updated:最新的3.0版讓版面變得有點討厭...不會自動換行,現在正在修改中...
就survey了兩套javascript library,心得與安裝方法如下:
1.google code prettify
如何安裝?
1.加入javascript與css到網頁上:
<script type="text/javascript src="http://google-code-prettify.googlecode.com/svn/trunk/src/prettify.js"></script> <link type="text/css" href="http://google-code-prettify.googlecode.com/svn/trunk/src/prettify.css"></link>*host on google code,未壓縮(57KB) 有網頁空間的可以自己下載來用
*http://jsgears.googlecode.com/svn/trunk/prettify.min/ 這裡有壓縮版(16KB)的檔案可以引用
2.於讀取網頁時執行語法高亮函式:
<body onload="prettyPrint">
如果與其他設定重複了可加入Event Handler:
<script type="text/javascript">
if(window.addEventListener){
addEventListener('load',function(){prettyPrint();},false);
}else{
attachEvent('onload',function(){prettyPrint();});
}
</script>
3.於想要加強語法效果處加入class="prettyprint":
<pre class="prettyprint">並可設定想加強的語法關鍵字:
<pre class="prettyprint lang-js">
2.Syntax Highlighter
如何安裝?
1.加入基本的javascript與css設定:
<link href='http://alexgorbatchev.com/pub/sh/current/styles/shCore.css'
rel='stylesheet' type='text/css'/>
<script src='http://alexgorbatchev.com/pub/sh/current/scripts/shCore.js'
type='text/javascript'></script>
*hosting on amazon s3,shCore.js為壓縮版(21K)2.加入要使用的語法以及css主題:
<link href='http://alexgorbatchev.com/pub/sh/current/styles/shThemeDefault.css' rel='stylesheet' type='text/css'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCpp.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCSharp.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCss.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushJava.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushJScript.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPhp.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPython.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushRuby.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushSql.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushVb.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushXml.js' type='text/javascript'></script> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPerl.js' type='text/javascript'></script>主題預覽可以看這個網頁:http://blog.cartercole.com/2009/10/awesome-syntax-highlighting-made-easy.html
3.執行Syntax Highlighter:
在blogger要多設定bloggerMode= true;
updated:最新的版本取消了這個功能,現在只要double click就可以選取全文
<script type='text/javascript'>
SyntaxHighlighter.config.bloggerMode = true;
SyntaxHighlighter.all();
</script>
4.於想要加強語法效果處加入class="brush: [語法]":
<pre class="brush:js;"
可設定無行號的light模式:
<pre class="brush:js;light:true;">
可指定行號加入強調效果:
<pre class="brush:js;highlight:[1];">
比較:
大小:兩者差不多,syntax highlighter要讀取比較多的語法檔與css主題,而prettify比較簡單
但syntax highlighter有官方的壓縮檔host
效果:syntax highlighter效果比較好,有行號,高亮,還有各種不同主題與剪貼簿功能
對應語言:各有長處,但syntax highlighter的語法檔比較好懂
不過最後我發現prettify在ie7會有把多行擠成一行的bug,
所以決定用Syntax Highlighter了 :)
updated:最新的3.0版讓版面變得有點討厭...不會自動換行,現在正在修改中...
[Html5Rocks!] 最好的Html5學習以及參考網頁

今天google code blog上釋出了一個html 5的推廣網頁
包含了互動式的slide show, 可以測試新功能的 html5 playground , 還有教學.
這可以說是接觸html5最好的網站了
它把html5定義為 html5 + new JSapi + CSS3 這一套完整的技術
看得出來google在推動新的網路技術上付出很多心血
原本html5預估要十年才能夠普及,但是由於新一代的瀏覽器以及mobile browser,ipad/phone對html5的支援,
越來越多的人開始注意到html5的可能性了
現在看來只有微軟還在拖慢Web技術的發展,
趕快想辦法解決一下你們的ie6...
弄個像chrome frame一樣的windows update啦
更多參考:
html5Demo
html5gallery
47-amazing-css3-animation-demo
7個簡單易學的特效範例
[Joy of Engineering Leadership]如何失去友誼與離間他人
Google I/O 2010: How to lose friends and alienate people: The joys of engineering leadership
這是Google I/O 中一場有關於如何領導團隊的演講:
以下是Wave上的筆記翻譯:
Ben和Fitz來到台上
這個講題是關於軟體工程的人事方面,大部分是我們的意見,如果你有不同的看法的話,你也可以開一個自己的講題 :-)
這裡有誰是管理者的?很多人舉手…
我們要先定義問題是什麼…如果你有一堆工程師,指派他們去完成一個專案、而沒有指定任何領導人,有人就會成為領導人,去分配工作,解決衝突等等,他們將自己放到更高的角度來看專案。這種情形稱為意外型管理者。
管理者是過時而要被淘汰的,而領導者是最搶手的新玩意。他們從工業革命以來的生產線式管理進化而來。當你要管理的是一個固定的流程時,糖果和鞭子的管理方式是很有用。但是當你要管理的是創意相關的工作時,糖果和鞭子就是一個災難了。
這造成了衝突,也是為什麼大家都討厭管理者的原因。典型的呆伯特式管理者的形象是;缺乏安全感,不受尊重,被雇用來監視大家,關心自己的晉升勝於他的團隊。
在大多數的公司中,傑出的工程師晉升到了頂端後,他們就必須進入管理階層,他們是好的工程師,卻也是不好的管理者。
什麼是Engineering Leader?
- 團隊中去排除障礙,服務團隊的人。
- 團隊中能夠信任的來源。
- 必須要能處理人際,但不能只會處理人際關係,他必須要有足夠的技術能力來了解發生什麼事。
- 最好的領導不是能輕易看見的,而是感覺到的。
ANTIPATTERNS
• 當每個人的朋友
• 你不可能永遠都是每個人的朋友,你必須能告訴大家壞消息,做出決策
• 像小孩一樣對待他人
• 如果你像小孩一樣對待別人,他們就會表現得像小孩。
• 不要Micro manage
• 相信別人會表現得像個大人並作出正確的事
• 如果你micromanage別人,他們就會表現得像小孩一樣。
• 雇用聽話的人:
• 最後你會雇用到只會聽命令辦事的人。
• 你必須要雇用比你聰明的人,並把他們帶往正確的方向。
• 在徵才的時候妥協
• 不得已的雇用還可以用的人,或是只雇用幾個人,不論來的人有多好。
• 忽略表現低落的人
• 沒有事情比忽略他們…還會拖累團隊,他們會讓你最好的人才出走。
• 當你等待太久,情況已經難以回復的時候,你只能選擇讓他們離開。
• 忽略人的問題。
• 人的問題比技術的問題難多了。
• 一個純粹的技術領導人,無法滿足每一個人社交方面的需求。
• 要關心團隊的 “開心等級” - EQ
PATTERNS
• 誠實
• 讚美三明治 : 在讚美中夾著壞消息。直接提供建設性的回饋會比較好,不過要委婉並保持同理心。
• 成為一個睿智的禪學大師
• 保持冷靜,保持專注,當問題發生時,和團隊一起工作並幫助團隊討論問題。
• 大多數的時候,團隊並不是真正的想要解決問題,你需要成為探測器,幫助他們冷靜下來討論問題。
• 放開自我。
• 這不代表要失去自信,而是要拋開自大的想法,團隊知道的比你更多。
• 相信你的團隊。
• 感謝別人的詢問,不要有什麼事情是我的範圍的想法,要保持宏觀的視野。
• 如果有人問你在做什麼,可能是因為他們有興趣,而不是在挑戰你。
• 道歉。
• 要人性化,保持謙虛。
• 謙虛 != 擦腳墊。 要有自信,不要成為獨行俠。
• 弄髒自己的手
• 到現場並且作事,這樣會幫助你了解團隊的問題。
• 委派
• 請求他人幫助,不要獨攬大權
• 找方法來替代自己,讓團隊成為運作良好的機器,不需要你就可以完成任務,這是領導很好的例子。
• 給別人更多責任,然後他們就會開始自己負責。
• 做出行動:
• 如果你看到了一個問題,你希望它會消失,那忽略它是一個很誘人的選擇,但你必須跳下去並做出行動,面對這個問題。
• 保護團隊免受高層或公司的政治影響。
• 當有人搞砸,大家都知道了,就不需要在團隊面前再羞辱他們一次。和他們談談,了解發生了什麼事,在公開場合稱讚,私底下評估失敗。
• 建立共識
• 當一個老師或是導師
• 當有新人加入團隊,讓他們去犯錯,犯錯是一種選擇,只要他們不會重複犯同樣的錯。
• 設定明確的目標。
• 除非妳定義了明確的目標,不然每個人都會對要做什麼,要完成什麼有不同的意見。
• 追蹤快樂度,有一個快樂指標。
• 問別人快不快樂。
• 問別人可以為他做什麼事,或他需要你提供什麼。
總結
工程師就像植物 – 他們有不同的需要。你的工作就是找到他們需要什麼,提供給他們。
散漫-> 有目標. 無趣 -> 有熱情.
內在與外在動機
- 外在動機來自外部,內在動機是最好的一種動機,讓人們能主動的去關心。
三種最好的內在動機:
• 自我管理 – 讓人們自己去了解問題,並相信他們能夠解決。
• 專精 – 讓人有機會學習並成長,我們都希望雇用最好的人才。要雇用最好的人才,就要讓他們能不斷成長,而不是拼命去燃燒他們,叫他們只做他們擅長的事。
• 目標 – 給別人一個目標意識,歸屬感,讓他們有自己的意見,想法,而不是聽命行事的齒輪。
管理你的管理者
工程師要怎麼幫助管理者?以下是幫助你更好被管理的方法:
• 表現得像個成人,沒有人監督你你也可以完成工作,不要表現得像是希望有人來監督你。
• 追求責任,表現你的成長,冒可接受的風險,允許犯錯。
• 與他人溝通,讓別人知道你在想什麼。
• 指出障礙,但不要一天到晚都在指出問題
• 主張自己的意見.
3 Walkaways
• 管理者服務他人。而不是讓其他人服務你。
• 所有的Pattern都與尊重有關
• 激勵別人,而不是用鞭子與糖果
• 停止做個管理者,開始做個領導者。
問題
Q: 如果你有很好的人才, 而別人想要你的人才, 要如何鼓勵他們留下?A: 想辦法扭轉這個情形,並專心在對你們團隊有益的事. 如果有人離開, 那不是妳的錯.
Q: 在管理自願性的專案上有什麼不同?
A: 在有薪水的環境下比較難, 自願性專案裡, 參與者是自己決定來參加的,他們有足夠的動機與興趣, 只是需要一些方向. 在公司裡,人們需要更多的內在動機.
Q: 當你的朋友要向你回報事情時,你如何處理?
A: 這可能會有點尷尬.當你需要傳達壞消息時,可能會很困難.
Q: 你如何處理你團隊成員在工作外的私人事務?
A: 以關懷與同理心處理是一個很好的界線, 如果你可以簡單的把他們換到另一個團隊, 你可以先觀察一下. 你可以和他們開誠佈公的談談這些事情.
Q: "每月最佳員工" 摧毀了團隊
A: 你也可以有”同事獎金”, 讓每個團隊成員有機會可以獎勵別人. 在團隊與個人的獎項之間,需要一些平衡.
[JQuery] 如何判斷元素是否存在
最近遇到了一個bug,
是因為jQuery沒有將事件綁定到指定的物件上所產生的
所以加上了檢查Html元素是否存在的邏輯:
可是結果還是一樣,括弧內的邏輯一定會執行到.
打開debugger檢查之後,發現Jquery使用了Null Object
就是即使找不到元素,JQuery還是會回傳一個空的JQuery物件.
讓對物件的操作不會因為null reference而產生錯誤.
但是Null Object的缺點就是,如果其他程式設計師不知道使用了Null Object,
就會寫出錯誤的檢查...像我一樣.
所以這裡應該檢查元素的length屬性,如果是空值的話就會傳回0:
由於javascript的boolean判斷會將0判斷成false,1以上的值判斷成true,
所以也可以這樣寫:
參考文章:http://www.aaronrussell.co.uk/blog/check-if-an-element-exists-using-jquery/
同場加映:
於內嵌的PDF IFrame讀取時使用jquery.blockUI:
是因為jQuery沒有將事件綁定到指定的物件上所產生的
所以加上了檢查Html元素是否存在的邏輯:
if($("#obj") != null){...}
可是結果還是一樣,括弧內的邏輯一定會執行到.
打開debugger檢查之後,發現Jquery使用了Null Object
就是即使找不到元素,JQuery還是會回傳一個空的JQuery物件.
讓對物件的操作不會因為null reference而產生錯誤.
但是Null Object的缺點就是,如果其他程式設計師不知道使用了Null Object,
就會寫出錯誤的檢查...像我一樣.
所以這裡應該檢查元素的length屬性,如果是空值的話就會傳回0:
if($("#obj").length > 0){...}
由於javascript的boolean判斷會將0判斷成false,1以上的值判斷成true,
所以也可以這樣寫:
if($("#obj").length){...}
參考文章:http://www.aaronrussell.co.uk/blog/check-if-an-element-exists-using-jquery/
同場加映:
於內嵌的PDF IFrame讀取時使用jquery.blockUI:
$(function() {
var iframe = $("#PDFiframe");
if(iframe.length){
//ie在綁定Iframe事件的時候會產生錯誤,必須要用windows.frames[]來取得iframe
//另外如果直接用jquery接frames物件的話,於判斷length時一定會傳回true...
if($.browser.msie){
iframe = $(frames["PDFiframe"]);
}
$.blockUI();
iframe.load(function() { $.unblockUI(); });
}
});
[Hollywood Principle] Dependency Injection Pattern
今天讀了Agile上面有關DIP的段落,乘機把它拿出來再複習一下:
首先,為什麼要用DIP呢?
書上舉了一個很好玩的例子來說明,叫"Hollywood Principle"
意思是"Don't Call me, I'll Call you"
好萊塢的經紀人不希望面試者主動聯絡他們,而是當他們決定要用你的時候才會主動聯絡。
以程式來說,就是讓物件自己決定要如何呼叫其他物件,而不是依賴於其他物件。
假設說今天我們要設計一個可以讀取Book資料的Reader
Reader依賴於book這個class的函式,
所以當我們要為這個程式增加可以閱讀EBook功能的時候,我們必須加入邏輯判斷來區別
第一個想到的就是新增TypeCode判斷,
於是醜陋的程式碼就產生了...
使用Dependency Injection Pattern,能使Reader這個Class不會被book這個class綁死,
相反的,Reader可以先宣告自己會使用的介面,等於是告訴其他Class
"我會用這個方式來呼叫你,如果你想讓我用的話,就先實做這個介面":
使用介面,或是abstract class來宣告使用的介面,
讓Reader這個class可以不被單一的Book class所綁死
只要是實作IBook這個介面的Class,Reader都可以使用
而這段程式碼在呼叫Reader的建構式時傳入它要使用的Book
這就是Dependency Injection(控制反轉)的一種
是當你要使用物件的時候才傳入物件之間的依賴關係,而不是在一開始就在程式碼中指定
這樣可以保持物件之間彼此的鬆散偶合,增加擴充性.
另外,在作單元測試時,DI也是很有用的一個Pattern
如果我們要測試Reader的Read()這個函式,但是Read這個函式又會呼叫到Book,
然後Book會連接到背後的資料物件...這樣我們無法知道說測試的成功或失敗,
是因為Reader的關係,還是Book,或是背後的資料庫的問題.
這個時候我們就可以使用Dependency Injection的特性,將Book與Reader之間的關係給切開,
先寫一個測試用的Book,實作IBook的介面,並且紀錄是否被呼叫:
利用這個方式,我們可以只測試我們想測試的邏輯.
也可以寫一個假的Data Access Class,將資料庫的部分先抽換掉,
來測試系統的介面與流程是否ok.
more:
Martin Flower提出的DI概念
良葛格對DI的詳細說明
首先,為什麼要用DIP呢?
書上舉了一個很好玩的例子來說明,叫"Hollywood Principle"
意思是"Don't Call me, I'll Call you"
好萊塢的經紀人不希望面試者主動聯絡他們,而是當他們決定要用你的時候才會主動聯絡。
以程式來說,就是讓物件自己決定要如何呼叫其他物件,而不是依賴於其他物件。
假設說今天我們要設計一個可以讀取Book資料的Reader
class Reader{
private Book book = new Book("Harry Potter");
public void read(int page){
book.read(page);
}
}
Reader依賴於book這個class的函式,
所以當我們要為這個程式增加可以閱讀EBook功能的時候,我們必須加入邏輯判斷來區別
第一個想到的就是新增TypeCode判斷,
於是醜陋的程式碼就產生了...
class Reader{
static final int BOOK = 1,EBOOK = 2;
public void read(int page, int bookType){
if(bookType = BOOK){
Book book = new Book("Harry Potter");
book.read(page);
}else if(bookType = EBOOK){
EBook book = new EBook("Harry Potter");
book.read(page);
}
}
}
使用Dependency Injection Pattern,能使Reader這個Class不會被book這個class綁死,
相反的,Reader可以先宣告自己會使用的介面,等於是告訴其他Class
"我會用這個方式來呼叫你,如果你想讓我用的話,就先實做這個介面":
class Reader{
private IBook book;
public void read(int page){
book.read(page);
}
public Reader(IBook book){
this.book = book;
}
}
class Book implement IBook{...}
class EBook implement IBook{...}
使用介面,或是abstract class來宣告使用的介面,
讓Reader這個class可以不被單一的Book class所綁死
只要是實作IBook這個介面的Class,Reader都可以使用
public Reader(IBook book){
this.book = book;
}
而這段程式碼在呼叫Reader的建構式時傳入它要使用的Book
這就是Dependency Injection(控制反轉)的一種
是當你要使用物件的時候才傳入物件之間的依賴關係,而不是在一開始就在程式碼中指定
這樣可以保持物件之間彼此的鬆散偶合,增加擴充性.
另外,在作單元測試時,DI也是很有用的一個Pattern
如果我們要測試Reader的Read()這個函式,但是Read這個函式又會呼叫到Book,
然後Book會連接到背後的資料物件...這樣我們無法知道說測試的成功或失敗,
是因為Reader的關係,還是Book,或是背後的資料庫的問題.
這個時候我們就可以使用Dependency Injection的特性,將Book與Reader之間的關係給切開,
先寫一個測試用的Book,實作IBook的介面,並且紀錄是否被呼叫:
public class TestBook implement IBook(){
public bool readed = false;
public void read(int page){
readed = true;
}
}
//測試案例:
public void ReaderTest(){
TestBook book = new TestBook()
Reader reader = new Reader(book);
reader.read();
assertTrue(book.readed);
}
利用這個方式,我們可以只測試我們想測試的邏輯.
也可以寫一個假的Data Access Class,將資料庫的部分先抽換掉,
來測試系統的介面與流程是否ok.
more:
Martin Flower提出的DI概念
良葛格對DI的詳細說明
[Translation] My Job Interview at Google
在網路上看到了My Job Interview at google這篇文章
覺得很有趣就把它翻成中文
內文如下:
我的Google面試經驗
差不多在兩個禮拜之前,我在Mountain View, California與Google的人員面試了! 這次與google的面試經驗非常的有意思,所以我想要和你們談談這次的經驗 (在發佈文章前,Google和我說了OK)
我面試的職位是Google SRE,SRE代表的是Site Reliability Engineering, Site Reliability Engineers(SREs) 同時是軟體工程師與系統管理員,負責Google服務開發到佈屬的全部過程。
總共有8次不同的面試,前三次是透過電話(電話面談)剩下的五次是實地面談,第一次面談是與招募人員,不是技術性的面談,但是剩下7次則非常的技術性
所有的面談都進行得很好,但我剛剛才知道我沒有被僱用!好吧…我個人認為進行得很好。我回答了所有問題,但看起來他們並不滿意!招募人員告訴我我的經驗不夠讓我能在一個處理緊急任務的Team工作,我應該多累積一點經驗然後再試一遍
以下是這件事發生的經過.
在我發佈了"Code Reuse in Google Chrome"這篇文章後Google的招募人員和我連繫,email上說:
一開始我想我會申請software developer這個職位,但是我和招募人員重新檢視了我的履歷與技能,他認為我更適合SRE這個位置.我也同意他的看法.這個職位看起來像是為我量身打造的.因為我同樣的喜歡當系統管理員和設計程式。
第一次面試(電話)
第一次是在9月10日與招募人員的面試.他和我說明了Google招募人員的流程並且檢視了我的履歷與技能. 我必須給我自己的技能從0到10打分數,像是C programming, C++ programming, Python programming, 網路,演算法,資料結構,分散式系統, Linux系統管理等等…
如我之前所說,根據我的回答我們認為SRE這個位置最適合我,一個SRE基本上需要會所有事情:演算法,資料結構,程式,網路,分散式系統,大型系統架構,排除問題.這是一個很適合hacker的位置!!
在這些問題之後他問我想在哪裡工作 – Google在愛爾蘭,蘇黎世,Mountain View或是澳洲的辦公室.我回答Mountain View因為那是Googleplex(google總公司)的所在地!他回答如果面試結果OK,我會拿到讓非美國公民可以在美國工作的H-18 visa.
下半段的面試是一些基本的技術問題,只是確認我知道這些東西.問題包括了Linux系統管理,演算法,電腦架構還有C
Programming.我不能透露更多細節,因為我簽了一份保密協議而且我的招募人員很友善的要求我不要發表這些問題!
我犯了一些小錯誤,但他覺得滿意了並和我排定了第二次的電話面談時間.他警告我下次的面談會非常的技術性,我最好做好準備.我請他給我充分的時間準備,所以我們排定了下次的面試時間為9月22日.
我開始發狂般的準備.我發現了三篇有關SRE是什麼的簡報:
• Engineering Reliability into Web Sites: Google SRE
• Google SRE: That Couldn't Happen to US... Could It?
• Google SRE: Chasing Uptime
然後我找了所有有關Google面試與面試問題的blog文章
• Corey Trager's Google Interview
• Rod Hilton's Google Interview
• Ben Watson's Google Interview
• Shaun Boyd's Google Interview
• How I Blew My Google Interview by Henry Blodget
• Get That Job at Google by Steve Yegge
• Tales from the Google's interview room
• Google Interview Questions
• Google Interview Questions -- Fun Brain Teasers!
• 還有更多...
我把Google的研究報告印出來讀了一遍
• The Google File System
• Bigtable: A Distributed Storage System for Structured Data
• MapReduce: Simplified Data Processing on Large Clusters
• 還有因為有趣而讀的Failure Trends in a Large Disk Drive Population
我也瀏覽了幾本書
• 網路基礎最好的書"TCP/IP Illustrated"
• 演算法最好的書"MIT's Introduction to Algorithms" + 我的演算法筆記
• 關於大型系統的書"Building Scalable Web Sites"
因為我不確定會不會被問到特定語言的問題,我看了一堆在C++ Cookbook, Python Cookbook, 和 Perl Cookbook的範例
第二次面試(電話)
第二次電話面試是和一個Google的工程師.他在負責AdSense與廣告的Ads team工作這次面試非常的技術性,從一個資料過大無法放入記憶體的演算法問題開始.我必須仔細的告訴他我會如何處理這個問題和我使用的資料結構與演算法,他也請我清楚的說明我的思考過程.之後他繼續問有關資料結構,DNS,TCP protocol, TCP相關的安全性問題,普遍的網路問題,還有Google本身.不過抱歉,我不能再透露更多的細節.
面試之後,那位工程師必須寫一份關於我的報告,結果是正面的-我可以繼續下一次面試.
我多給了自己一點時間來準備第三次面試,時間是十月1日.與一位Google traffic team的人面試,這次面試有一個很簡單的程式問題,然後我必須透過電話來寫程式. 可以自己選擇語言,所以我選了Perl因為那是我最喜歡的程式語言. 不過因為很難透過電話說明Perl的語法: "在這個金錢符號元素處開啟變數在資料處關閉變數開啟括號……關閉括號" 所以我透過email傳送我的Perl程式.
然後進一步討論同樣的問題,如果我們處理的資料是以Gigabyte計,以Terabyte計.我的程式/解決方法會如何改變?然後我又被問了一個有關DNS的問題,然後是HTTP protocol,routing, 和 TCP資料傳輸.
結果是正面的,我可以準備去Google面試了. 我從我的招募人員知道會有五次面試, 每次45分鐘長. 一次是我之前的工作經驗,一次是演算法和資料結構,一次是Trouble shooting和網路,然後兩次關於C與C++的軟體開發.
我的招募人員建議我讀這些文章:
• Google C++ Style Guide
• Web Search for a Planet: The Google Cluster Architecture
• Algorithm Tutorials on TopCoder
我在十月24日下午1點從Latvia出發然後在下午八點到加州.實際上飛了14個小時,但由於我是往時差減少的方向飛,我省了7個小時.實地面試安排在十月27日,所以我可以在面試前好好休息. Google也很慷慨的幫我付了旅費,交通費與食物.我沒花任何一毛錢!
第四次面試
第四次面試終於到了GooglePlex!早上十點我與我的招募人員會面,我們花了15分鐘討論面試.他告訴我我會先有兩次面試,然後一個Google的工程師會帶我到Google的餐廳吃午飯,下午則是另外三次面試.
早上10點15,第一輪的面試開始. 是關於我之前的工作經驗. 我過去有許多工作經驗,而我決定和他們談論關於一個我幾年前以C和Linux開發的安全通報系統.這個系統會從serial port接收訊息然後送出Email與簡訊.
最後幾分鐘他問我一些基本的Unix檔案系統問題
在所有的面試中,我都可以在兩片大白板上面畫圖與寫字.真有趣!
第五次面試
第五次面試於早上11點開始.是關於coding的部分,由一個有點技巧的問題開始,但不是實際上的coding問題.我被要求以C來實做我的答案.答案是數學的演算式以及一行的Return statement.沒有大量的Coding.然後我被要求以一些知名的資料結構來實作.在coding的時候我犯了一個錯誤和忘記初始化一部分我已經malloc()了的資料!這個問題在實際開發時會產生Segfault(註:Segmentation error)然後會被找出來,但Google的工程師很重視這個問題!如果你有面試機會的話,千萬別犯任何錯誤!
這次面試結束後,我被第二次和我電話面試的Google工程師帶到餐廳吃午飯,她說她在Google工作了兩年了, 她覺得在這裡工作很快樂.我們去了一家亞洲食物的餐廳(在Google plex內),我吃了很多食物,都很好吃,而且全部免費!
然後她帶我到Googleplex內四處逛逛,非常令人讚嘆.到處都是免費的飲料與糖果,還有一些大台電玩,外面有沙灘排球場,還有很多令人驚訝的東西.
第六次面試
第六次面試開始於下午12:45.是關於Troubleshooting和網路的面試.面試者在白板上畫了一個網路圖然後想像在這裡發生了一個問題.我必須問一堆關於網路細節的問題來找出問題在哪.他很滿意並在最後幾分鐘問了我一些網路設備的細節問題.
第七次面試:
第七次面試從下午1:30開始.是coding面試.我被要求用C或C++實做一個操作String的subroutine.我選了C.不幸的是我在這裡犯了off-by-one的錯誤 – 人類歷史上最常犯的程式錯誤. 整個面試就集中在這個問題上.
第八次面試
最後,第八次面試於下午2:15開始,是關於資料結構與演算法的面試.這裡的問題和第二次面試很像.但是他的問題不只是資料大到無法放入記憶體,同時資料也是分散的.所以我必須想很多方法來解決他.這次面試的過程很自由,而我們從頭到尾討論了這個問題.我在最後找到了正確答案,他說沒有幾個面試者最後能得出這個答案的.我很高興.
面試結束後工程師帶我到大廳,幫我叫了計程車回旅館.就這樣結束了! :)
結尾:
總的來說與Google的面試過程對我來說是一種樂趣,面試的問題很技術性,但不是非常挑戰性的或困難的問題.
感謝Google提供我這次機會! :)
覺得很有趣就把它翻成中文
內文如下:
我的Google面試經驗
差不多在兩個禮拜之前,我在Mountain View, California與Google的人員面試了! 這次與google的面試經驗非常的有意思,所以我想要和你們談談這次的經驗 (在發佈文章前,Google和我說了OK)
我面試的職位是Google SRE,SRE代表的是Site Reliability Engineering, Site Reliability Engineers(SREs) 同時是軟體工程師與系統管理員,負責Google服務開發到佈屬的全部過程。
總共有8次不同的面試,前三次是透過電話(電話面談)剩下的五次是實地面談,第一次面談是與招募人員,不是技術性的面談,但是剩下7次則非常的技術性
所有的面談都進行得很好,但我剛剛才知道我沒有被僱用!好吧…我個人認為進行得很好。我回答了所有問題,但看起來他們並不滿意!招募人員告訴我我的經驗不夠讓我能在一個處理緊急任務的Team工作,我應該多累積一點經驗然後再試一遍
以下是這件事發生的經過.
在我發佈了"Code Reuse in Google Chrome"這篇文章後Google的招募人員和我連繫,email上說:
我們Google正在招募最頂尖的軟體工程師.而我在有可能成為世界級工程師的名單上找到了你,
我希望能夠更瞭解妳.我也保證會提供你更多有關我們的資訊.
有興趣想要知道更多嗎?想要在Google成為一個有影響力的Player嗎?
請回覆你現在的履歷表(英文)副本,我很樂意與你連繫更多細節.
一開始我想我會申請software developer這個職位,但是我和招募人員重新檢視了我的履歷與技能,他認為我更適合SRE這個位置.我也同意他的看法.這個職位看起來像是為我量身打造的.因為我同樣的喜歡當系統管理員和設計程式。
第一次面試(電話)
第一次是在9月10日與招募人員的面試.他和我說明了Google招募人員的流程並且檢視了我的履歷與技能. 我必須給我自己的技能從0到10打分數,像是C programming, C++ programming, Python programming, 網路,演算法,資料結構,分散式系統, Linux系統管理等等…
如我之前所說,根據我的回答我們認為SRE這個位置最適合我,一個SRE基本上需要會所有事情:演算法,資料結構,程式,網路,分散式系統,大型系統架構,排除問題.這是一個很適合hacker的位置!!
在這些問題之後他問我想在哪裡工作 – Google在愛爾蘭,蘇黎世,Mountain View或是澳洲的辦公室.我回答Mountain View因為那是Googleplex(google總公司)的所在地!他回答如果面試結果OK,我會拿到讓非美國公民可以在美國工作的H-18 visa.
下半段的面試是一些基本的技術問題,只是確認我知道這些東西.問題包括了Linux系統管理,演算法,電腦架構還有C
Programming.我不能透露更多細節,因為我簽了一份保密協議而且我的招募人員很友善的要求我不要發表這些問題!
我犯了一些小錯誤,但他覺得滿意了並和我排定了第二次的電話面談時間.他警告我下次的面談會非常的技術性,我最好做好準備.我請他給我充分的時間準備,所以我們排定了下次的面試時間為9月22日.
我開始發狂般的準備.我發現了三篇有關SRE是什麼的簡報:
• Engineering Reliability into Web Sites: Google SRE
• Google SRE: That Couldn't Happen to US... Could It?
• Google SRE: Chasing Uptime
然後我找了所有有關Google面試與面試問題的blog文章
• Corey Trager's Google Interview
• Rod Hilton's Google Interview
• Ben Watson's Google Interview
• Shaun Boyd's Google Interview
• How I Blew My Google Interview by Henry Blodget
• Get That Job at Google by Steve Yegge
• Tales from the Google's interview room
• Google Interview Questions
• Google Interview Questions -- Fun Brain Teasers!
• 還有更多...
我把Google的研究報告印出來讀了一遍
• The Google File System
• Bigtable: A Distributed Storage System for Structured Data
• MapReduce: Simplified Data Processing on Large Clusters
• 還有因為有趣而讀的Failure Trends in a Large Disk Drive Population
我也瀏覽了幾本書
• 網路基礎最好的書"TCP/IP Illustrated"
• 演算法最好的書"MIT's Introduction to Algorithms" + 我的演算法筆記
• 關於大型系統的書"Building Scalable Web Sites"
因為我不確定會不會被問到特定語言的問題,我看了一堆在C++ Cookbook, Python Cookbook, 和 Perl Cookbook的範例
第二次面試(電話)
第二次電話面試是和一個Google的工程師.他在負責AdSense與廣告的Ads team工作這次面試非常的技術性,從一個資料過大無法放入記憶體的演算法問題開始.我必須仔細的告訴他我會如何處理這個問題和我使用的資料結構與演算法,他也請我清楚的說明我的思考過程.之後他繼續問有關資料結構,DNS,TCP protocol, TCP相關的安全性問題,普遍的網路問題,還有Google本身.不過抱歉,我不能再透露更多的細節.
面試之後,那位工程師必須寫一份關於我的報告,結果是正面的-我可以繼續下一次面試.
我多給了自己一點時間來準備第三次面試,時間是十月1日.與一位Google traffic team的人面試,這次面試有一個很簡單的程式問題,然後我必須透過電話來寫程式. 可以自己選擇語言,所以我選了Perl因為那是我最喜歡的程式語言. 不過因為很難透過電話說明Perl的語法: "在這個金錢符號元素處開啟變數在資料處關閉變數開啟括號……關閉括號" 所以我透過email傳送我的Perl程式.
然後進一步討論同樣的問題,如果我們處理的資料是以Gigabyte計,以Terabyte計.我的程式/解決方法會如何改變?然後我又被問了一個有關DNS的問題,然後是HTTP protocol,routing, 和 TCP資料傳輸.
結果是正面的,我可以準備去Google面試了. 我從我的招募人員知道會有五次面試, 每次45分鐘長. 一次是我之前的工作經驗,一次是演算法和資料結構,一次是Trouble shooting和網路,然後兩次關於C與C++的軟體開發.
我的招募人員建議我讀這些文章:
• Google C++ Style Guide
• Web Search for a Planet: The Google Cluster Architecture
• Algorithm Tutorials on TopCoder
我在十月24日下午1點從Latvia出發然後在下午八點到加州.實際上飛了14個小時,但由於我是往時差減少的方向飛,我省了7個小時.實地面試安排在十月27日,所以我可以在面試前好好休息. Google也很慷慨的幫我付了旅費,交通費與食物.我沒花任何一毛錢!
第四次面試
第四次面試終於到了GooglePlex!早上十點我與我的招募人員會面,我們花了15分鐘討論面試.他告訴我我會先有兩次面試,然後一個Google的工程師會帶我到Google的餐廳吃午飯,下午則是另外三次面試.
早上10點15,第一輪的面試開始. 是關於我之前的工作經驗. 我過去有許多工作經驗,而我決定和他們談論關於一個我幾年前以C和Linux開發的安全通報系統.這個系統會從serial port接收訊息然後送出Email與簡訊.
最後幾分鐘他問我一些基本的Unix檔案系統問題
在所有的面試中,我都可以在兩片大白板上面畫圖與寫字.真有趣!
第五次面試
第五次面試於早上11點開始.是關於coding的部分,由一個有點技巧的問題開始,但不是實際上的coding問題.我被要求以C來實做我的答案.答案是數學的演算式以及一行的Return statement.沒有大量的Coding.然後我被要求以一些知名的資料結構來實作.在coding的時候我犯了一個錯誤和忘記初始化一部分我已經malloc()了的資料!這個問題在實際開發時會產生Segfault(註:Segmentation error)然後會被找出來,但Google的工程師很重視這個問題!如果你有面試機會的話,千萬別犯任何錯誤!
這次面試結束後,我被第二次和我電話面試的Google工程師帶到餐廳吃午飯,她說她在Google工作了兩年了, 她覺得在這裡工作很快樂.我們去了一家亞洲食物的餐廳(在Google plex內),我吃了很多食物,都很好吃,而且全部免費!
然後她帶我到Googleplex內四處逛逛,非常令人讚嘆.到處都是免費的飲料與糖果,還有一些大台電玩,外面有沙灘排球場,還有很多令人驚訝的東西.
第六次面試
第六次面試開始於下午12:45.是關於Troubleshooting和網路的面試.面試者在白板上畫了一個網路圖然後想像在這裡發生了一個問題.我必須問一堆關於網路細節的問題來找出問題在哪.他很滿意並在最後幾分鐘問了我一些網路設備的細節問題.
第七次面試:
第七次面試從下午1:30開始.是coding面試.我被要求用C或C++實做一個操作String的subroutine.我選了C.不幸的是我在這裡犯了off-by-one的錯誤 – 人類歷史上最常犯的程式錯誤. 整個面試就集中在這個問題上.
第八次面試
最後,第八次面試於下午2:15開始,是關於資料結構與演算法的面試.這裡的問題和第二次面試很像.但是他的問題不只是資料大到無法放入記憶體,同時資料也是分散的.所以我必須想很多方法來解決他.這次面試的過程很自由,而我們從頭到尾討論了這個問題.我在最後找到了正確答案,他說沒有幾個面試者最後能得出這個答案的.我很高興.
面試結束後工程師帶我到大廳,幫我叫了計程車回旅館.就這樣結束了! :)
結尾:
總的來說與Google的面試過程對我來說是一種樂趣,面試的問題很技術性,但不是非常挑戰性的或困難的問題.
感謝Google提供我這次機會! :)
Subscribe to:
Comments (Atom)